소련 미사일 방어 시스템의 탄생. "엘 버로스"

Burtsev는 교사로부터 서양 프로토 타입에 대한 사랑과 존경을 물려 받았습니다. 예, 원칙적으로 BESM-6부터 ITMiVT는 주로 미국의 IBM 및 영국의 맨체스터 대학교와 적극적으로 정보를 교환했습니다. 1969년의 기억에 남을 회의에서 독일 Robotron이 아니라 영국 ICL의 이익을 위해 로비를 하도록 Lebedev(h. 포함)를 강요했습니다.
당연히 "Elbrus"는 프로토 타입을 가질 수 없었고 Burtsev 자신도 이것을 공개적으로 인정합니다.
대답은 분명합니다. "예"입니다. 새 컴퓨터를 설계하기 시작하기 전에 우리는 항상 이 분야에서 전 세계의 발전을 매우 주의 깊게 연구했습니다.
당시 고급 언어로 작성된 프로그램의 통과 효율을 높이기 위해 고급 언어와 명령 언어의 격차를 줄이기 위해 기계어 수준을 높이는 것이 문제였다.
이 방향으로 세계에서 세 곳에서 일했습니다.
이론적 측면에서 Ailif의 작업은 가장 강력했습니다. "기본 기계 구성을 위한 원칙"은 맨체스터 대학의 Kilburn 및 Edwards 연구소에서 MU-5 기계("Manchester University-5")가 만들어졌습니다. Burrows에서는 은행 및 군용 기계가 개발되었습니다.
저는 세 회사 모두에 있었고 주요 개발자들과 이야기를 나누었고 이러한 개발에 구현된 원칙에 대한 필요한 자료를 받았습니다.
Elbrus-1 및 Elbrus-2 MVK를 설계할 때 고급 개발에서 우리에게 가치 있는 모든 것을 가져왔습니다. 이것이 모든 새로운 기계가 만들어지고 개발되어야 하는 방법입니다.
MVK Elbrus-1 및 Elbrus-2의 개발은 HP, 5E26, BESM-6의 아키텍처 및 당시의 기타 여러 개발의 영향을 받았습니다.
당시 고급 언어로 작성된 프로그램의 통과 효율을 높이기 위해 고급 언어와 명령 언어의 격차를 줄이기 위해 기계어 수준을 높이는 것이 문제였다.
이 방향으로 세계에서 세 곳에서 일했습니다.
이론적 측면에서 Ailif의 작업은 가장 강력했습니다. "기본 기계 구성을 위한 원칙"은 맨체스터 대학의 Kilburn 및 Edwards 연구소에서 MU-5 기계("Manchester University-5")가 만들어졌습니다. Burrows에서는 은행 및 군용 기계가 개발되었습니다.
저는 세 회사 모두에 있었고 주요 개발자들과 이야기를 나누었고 이러한 개발에 구현된 원칙에 대한 필요한 자료를 받았습니다.
Elbrus-1 및 Elbrus-2 MVK를 설계할 때 고급 개발에서 우리에게 가치 있는 모든 것을 가져왔습니다. 이것이 모든 새로운 기계가 만들어지고 개발되어야 하는 방법입니다.
MVK Elbrus-1 및 Elbrus-2의 개발은 HP, 5E26, BESM-6의 아키텍처 및 당시의 기타 여러 개발의 영향을 받았습니다.
따라서 Burtsev는 많은 사람들과 달리 이웃에게서 건축 아이디어를 관대하게 차용하는 것을 주저하지 않았으며 꼬리를 찾을 곳도 말합니다.
넉넉한 제안을 활용하여 Elbrus의 세 가지 소스와 세 가지 구성 요소를 파헤쳐 보겠습니다.

첫 번째는 John Iiffe의 모노그래프 Basic Machine Principles(Macdonald & Co; 1st edition, 1년 1968월 12일)와 그의 기사 Elements of BLM(The Computer Journal, Volume 3, Issue 1969, August 251, Pages 258–5)입니다. 맨체스터 대학에서 실험용으로 만든 거의 알려지지 않은 MU700 컴퓨터이고 세 번째는 Burroughs XNUMX 시리즈입니다.
Burroughs 자신의 클론이 아닌가?
순서대로 이해를 시작합시다.
첫째, 독자 중 일부는 자랑의 맥락에서 종종 사용되는 "폰 노이만 아키텍처"라는 용어를 들었을 것입니다. "여기서 우리는 독특한 비 폰 노이만 컴퓨터를 설계했습니다." 폰 노이만 아키텍처의 기계가 1950년대에 더 이상 제작되지 않았기 때문에 당연히 이것에 독특한 것은 없습니다.
ENIAC 작업 후 EDSAC라고 불리는 기계는 Mauchly와 Eckert가 설계에 대한 주요 아이디어를 제시했습니다.
그것들은 다음과 같습니다: 명령, 주소 및 데이터를 저장하는 동종 메모리, 액세스 방법 및 발생하는 영향만 서로 다릅니다. 메모리는 주소 지정 가능한 셀로 나누어져 액세스하려면 이진 주소를 계산해야 합니다. 마지막으로 프로그램 제어의 원리 - 기계의 작동은 동일한 셀에서 순차적으로 로드되는 명령의 제어하에 메모리에서 셀의 내용을 로드하고 조작하고 메모리로 다시 언로드하는 일련의 작업입니다. 메모리.
1945년에서 1955년 사이에 세계에서 생산된 거의 모든 기계(그리고 불과 수십 대에 불과함)는 이러한 원칙을 따랐습니다. Herman Heine Goldstine의 큐레이터 폰 노이만(von Neumann)이 그를 대신합니다.
당연히 이것은 오래 갈 수 없었습니다. 왜냐하면 순수한 폰 노이만 기계는 튜링 기계와 같은 수학적 추상화였기 때문입니다. 과학적인 목적으로 사용하는 것은 유용했지만 이러한 아이디어에 따라 구축된 실제 컴퓨터는 너무 느린 것으로 나타났습니다.
순수한 폰 노이만 기계의 시대는 사람들이 파이프라인, 투기적 실행, 데이터 기반 아키텍처 및 기타 그러한 트릭에 대해 처음으로 생각하기 시작한 1955-1956년에 이미 끝났습니다.
폰 노이만이 사망한 해에 5개의 램프, 190개의 다이오드, 3개의 트랜지스터를 갖춘 MANIAC II 컴퓨터(수학적 분석기 수치 적분기 및 자동 컴퓨터 모델 II)가 Los Alamos 과학 연구소에서 출시되었습니다.
48비트 데이터와 24비트 명령어에서 실행되었으며 4워드의 RAM이 있으며 평균 속도는 096KIPS입니다.
이 기계는 근본적으로 새로운 아이디어를 제안한 Martin H. Graham이 설계했습니다. 메모리의 데이터를 적절한 태그로 표시하여 신뢰성을 높이고 프로그래밍을 쉽게 하는 것입니다.
다음 해에 Graham은 텍사스 휴스턴에 있는 Rice University의 직원들로부터 로스 알라모스만큼 강력한 컴퓨터를 만드는 일을 돕도록 초대받았습니다. R1 Rice Institute Computer 프로젝트는 1961년 동안 지속되었으며 7040년에 기계가 준비되었습니다(나중에 이 기계는 미국의 진지한 대학을 위한 표준 IBM 5500, 그리고 아이러니하게도 Burroughs BXNUMX으로 대체되었습니다).
MANIAC II에서와 같이 워드당 2개 명령어의 디코딩 방식은 Graham에게 너무 화려해 보였기 때문에 R1은 전체 워드에 대해 고정 너비 명령어로 54비트 워드에서 작동했으며 유사한 태그 아키텍처를 가졌습니다. 실제 워드 길이는 63비트였으며 그 중 7개는 오류 수정 코드이고 2개는 태그였습니다.
R1의 간접 주소 지정 메커니즘은 IBM 709보다 훨씬 더 발전했습니다. Graham은 또한 재능 있는 전기 엔지니어였으며 R1을 위한 새로운 유형의 튜브 다이오드 셀인 Single Sided Gate를 발명했는데, 이를 통해 그 기간 동안 1MHz의 우수한 주파수를 달성할 수 있었습니다. 기계에는 15비트 주소, 8개의 데이터/명령 레지스터 및 8개의 주소 레지스터가 있습니다.

1세대 태그 아키텍처는 폰 노이만이 사망한 직후 문자 그대로 등장했습니다. Ailif와 Graham의 기계(왼쪽은 MANIAC II 프로세서의 일부이고 오른쪽은 Ailif 자신이 메인 랙 RXNUMX 설치에 참여하고 있음)입니다. 사진 https://www.sciencephoto.com 및 https://scholarship.rice.edu
미국 라이스 대학교는 소련의 MINEP와 비슷하기 때문에 (석유의 유체 역학을 연구하는 데 사용될 예정인) 컴퓨터의 제작이 Shell Oil Company에서 부분적으로 자금을 지원받았다는 것은 놀라운 일이 아닙니다.
그녀의 큐레이터는 재능 있는 전자 엔지니어인 Bob Barton(Robert Stanley Barton)이었습니다. 1958년에 수학 논리와 대수학에 적용된 폴란드어 표기법 과정을 수강하고 Burroughs에서 일하게 되었으며 1961년에는 스택 태그 아키텍처를 기반으로 전설적인 B5000을 구축했습니다.
동일한 Briton Iif가 R1 소프트웨어에서 작업했습니다. 그의 팀은 OOP의 전신 중 하나가 된 SPIREL 운영 체제, AP1 기호 어셈블러 및 GENIE 언어를 만들었습니다. OS는 엄청나게 진보된 동적 메모리 할당 메커니즘과 가비지 수집기, 데이터 및 코드 보호 메커니즘을 갖추고 있습니다.
Ailif는 자신의 운영 체제에서 데이터 벡터에 대한 포인터 벡터를 사용하여 새로운 배열 주소 지정 메커니즘을 개발했습니다. 이 아이디어는 Fortran 스타일 주소 지정(주소에는 배열의 각 요소에 대한 단계 및 오프셋이 포함됨)보다 훨씬 발전되어 작성자의 이름을 따서 명명되었으며 그 이후로 Ailif 벡터는 Ferranti Atlas에서 Java에 이르기까지 모든 곳에서 사용되었습니다. Python, Ruby, Visual Basic .NET, Perl, PHP, JavaScript, Objective-C 및 Swift.
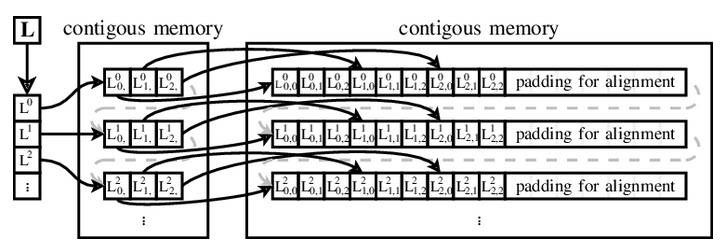
Ailif 벡터를 사용하여 3x3 매트릭스를 처리합니다(https://www.researchgate.net).
1950년대 후반에 폰 노이만의 이론적인 기계 모델은 적절한 답이 없는(따라서 완전히 죽은) 도전에 직면했습니다.
컴퓨터는 한 사람만이 작업을 로드할 수 없을 정도로 빨라졌습니다. 터미널 액세스와 멀티태스킹 운영 체제가 있는 클래식 메인프레임의 개념이 등장했습니다.
우리는 멀티태스킹으로 가는 길에 아키텍트를 기다리는 복잡성에 대해 깊이 파고들지 않을 것입니다(운영 체제 설계에 대한 합리적인 교과서가 이에 대해 설명할 것입니다). 우리는 코드 재진입이 구현, 즉 여러 인스턴스를 실행할 수 있는 능력에 중요하다는 점에 주목합니다. 한 사용자의 데이터가 다른 사용자의 변경 사항으로부터 보호되도록 다른 데이터에 대해 작업하면서 같은 프로그램을 동시에 사용합니다.
이 모든 문제를 OS 설계자와 시스템 프로그래머의 수장에게 전적으로 맡기는 것은 그다지 좋은 생각이 아닌 것 같았습니다. 소프트웨어 개발의 복잡성이 너무 많이 증가했을 것입니다(OS / 360 프로젝트가 어떻게 엄청난 실패로 끝났는지 기억하십시오. Multics도 그렇지 않았습니다. 이륙하다).
컴퓨터 자체에 적합한 아키텍처를 만드는 대안도 있었습니다.
B1을 설계한 실무자 Barton과 Burtsev에게 많은 영감을 준 바로 그 Basic Machine Principles를 저술한 이론가 Ailif 등 R5000의 동료들이 거의 동시에 이러한 가능성을 고려했습니다.
ICL(우리가 한 번도 협력한 적이 없음)은 1963년부터 1968년까지 고급 아키텍처의 개발을 주도했으며(이 기사가 작성된 작업을 기반으로 했습니다) Iif는 하드웨어 메모리 관리 방법을 훨씬 더 발전시킨 BLM 프로토타입을 구축했습니다. Burroughs 기계보다.
Ailif의 주요 아이디어는 순전히 소프트웨어 방식에 기반한 다른 시스템(그리고 그 당시 느리고 비효율적인) 메모리 공유 메커니즘에 대한 표준을 피하려는 시도였습니다. 하나의 실행 중인 프로세스를 언로드 및 저장하고 다른 프로세스의 로드 및 실행 시작) 운영 체제 자체에 의해. 그의 관점에서 디스크립터를 사용하는 하드웨어 접근 방식은 훨씬 더 효율적이었습니다.
BLM 프로젝트는 1969년에 종료되었지만 그 개발은 2900년에 출시된 고급 ICL 1974 시리즈 메인프레임 라인에서 부분적으로 사용되었습니다.
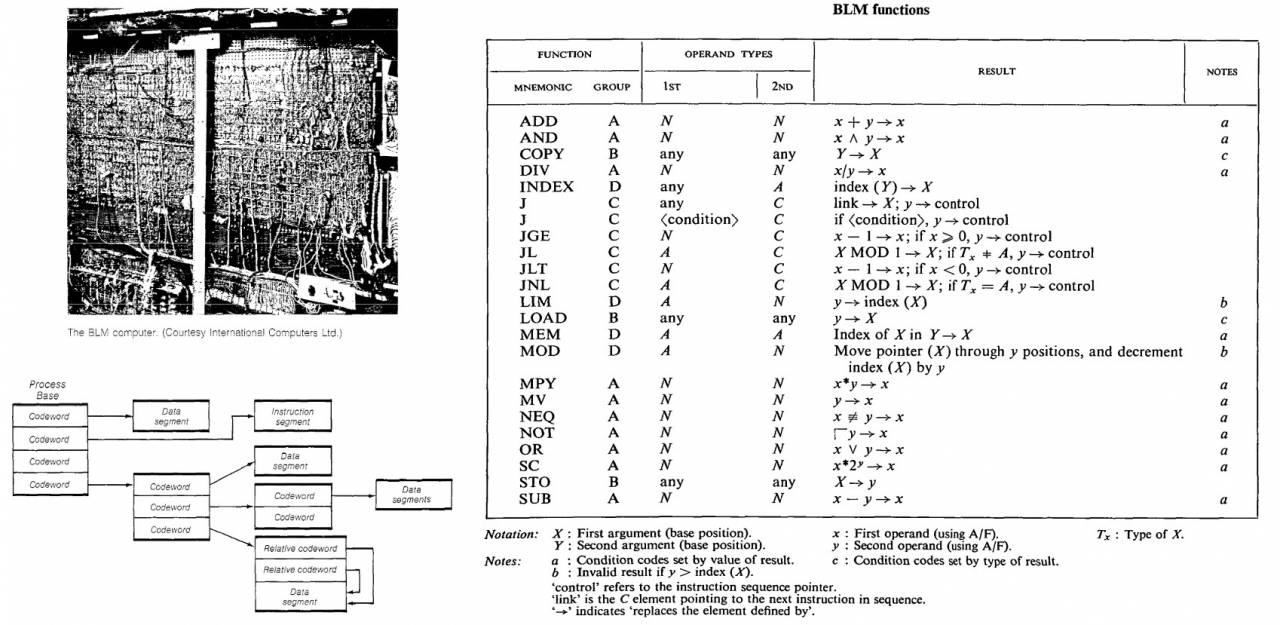
불행히도 이미 태그 디스크립터 시스템의 1984세대는 BLM에서 남아 있는 디스크립터 기반 컴퓨터 시스템(Levy, Henry M. XNUMX) 책의 이 사진뿐입니다. 명령 시스템은 Ailif의 원본 기사에서 재현됩니다(독자가 Burtsev 이후 문제에 몰입할 수 있도록).
당연히 효과적인 메모리 보호(따라서 시간 공유) 문제는 1960년대에 거의 모든 컴퓨터 과학자와 기업의 관심사였습니다.
맨체스터 대학은 제 5의 컴퓨터인 MUXNUMX를 만들지 않았습니다.
이 기계는 1966년부터 동일한 ICL과 협력하여 개발되었으며 컴퓨터는 성능면에서 Ferranti Atlas보다 20배 더 빠릅니다. 개발은 1969년부터 1974년까지 계속되었습니다.
MU5는 MUSS 운영 체제에 의해 제어되었으며 5개의 프로세서(MU1905 자체, ICL 11E 및 PDP-XNUMX)를 포함했습니다. 태그 디스크립터 아키텍처, 연관 메모리, 명령어 프리페칭과 같은 가장 진보된 요소를 모두 사용할 수 있었습니다. 이는 그 당시 기술의 정점이었습니다.
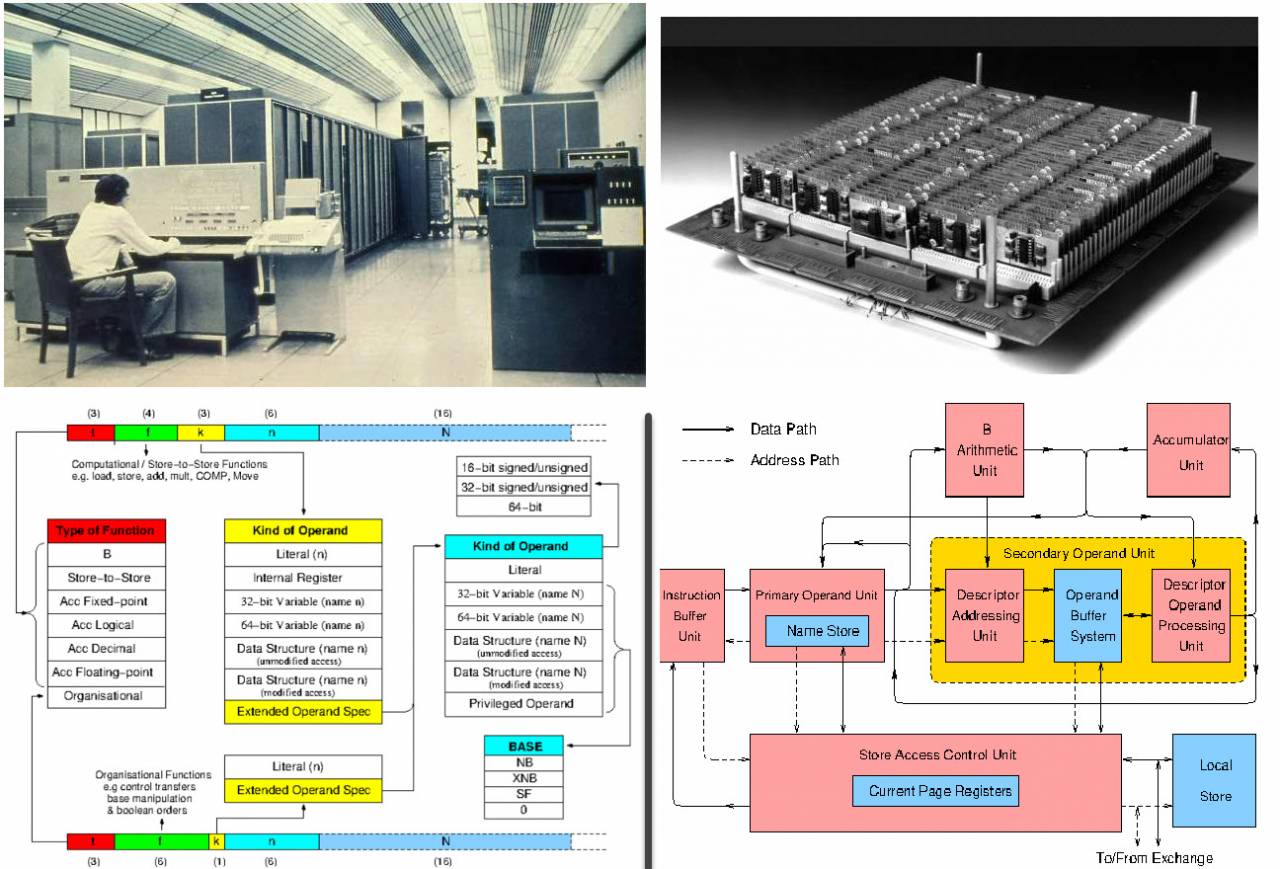
Manchester Machine 5 - 유일한 사진, 명령 시스템 및 아키텍처에 대한 탁월한 설명(https://ethw.org)
MU5는 ICL 2900 시리즈의 기반이 되었으며 1982년까지 대학에서 근무했습니다.
맨체스터의 마지막 컴퓨터는 MU6으로 세 대의 기계로 구성되었습니다. MU66P, PC로 사용되는 고급 마이크로프로세서 구현; MU66G는 강력한 스칼라 과학 슈퍼컴퓨터이고 MU66V는 벡터 병렬 시스템입니다.
과학자들은 마이크로프로세서 아키텍처의 개발을 마스터하지 못했고 MU66G는 1982년부터 1987년까지 부서에서 만들어지고 작업했으며 MU66V의 경우 벡터 작업 에뮬레이션을 사용하여 Motorola 68k에 프로토타입이 구축되었습니다.

ICL 2900 시리즈는 S/360과 상당히 치열하게 경쟁한 몇 안 되는 오리지널 머신 중 하나였습니다. 1980년대 영국 사용자들에게 이 시리즈는 소련의 BESM-6처럼 따뜻함과 향수가 가득하다. 사진 http://www.tavi.co.uk 및 http://www.computinghistory.org.uk
디스크립터 머신의 추가 발전은 소위 체계였습니다. 기능 기반 주소 지정(문자 그대로 "기능 기반 주소 지정"은 러시아어로 잘 번역된 번역이 없습니다. Myers GJ, 2) 이는 매우 적절하게 이름이 지정된 잠재적 주소 지정)입니다.
잠재적인 주소 지정의 의미는 포인터가 OS 커널의 특별한 권한 있는 프로세스에 의해서만 실행되는 권한 있는 명령의 도움으로만 생성될 수 있는 특별한 보호 개체로 대체된다는 것입니다. 이를 통해 커널은 별도의 주소 공간을 전혀 사용하지 않고 컨텍스트 전환의 오버헤드 없이 메모리의 어떤 개체에 액세스할 수 있는 프로세스를 제어할 수 있습니다.
간접적인 효과로 이러한 방식은 동종 또는 평면 메모리 모델로 이어집니다. 이후에는 (저수준 드라이버 프로그래머의 관점에서도!) RAM 또는 디스크에 있는 개체 간에 인터페이스 차이가 없으며 액세스가 보호 개체에 대한 호출을 사용하여 절대적으로 균일합니다. 개체 목록은 특수 메모리 세그먼트(예: 250-1969년에 생성된 Plessey System 1972에서 λ-calculus라고 하는 매우 난해한 계산 모델의 하드웨어 구현)에 저장하거나 다음으로 인코딩할 수 있습니다. 프로토타입 IBM System /38에서와 같이 특별한 비트.
Plessey System 250은 군용으로 개발된 것으로, 걸프전 당시 국방부 통신망의 중추기관으로 성공적으로 사용되었습니다.
이 컴퓨터는 네트워크 보안의 절대적인 정점이었고, 클래스로서 무제한의 권한을 가진 수퍼유저가 없었고, 해서는 안 되는 일을 하기 위해 해킹을 통해 자신의 권한을 높일 수 있는 방법이 없었습니다.
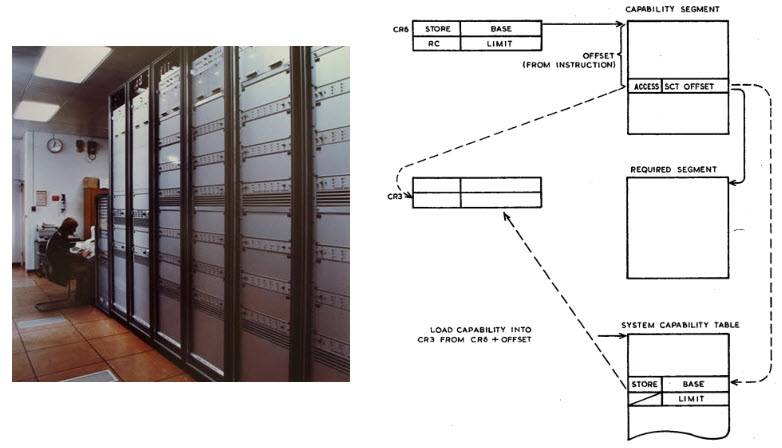
Pless 250 유일한 알려진 사진(Kenneth J Hamer-Hodges 컬렉션에서) 및 모노그래프 Capability Concept Mechanisms And Structure In System 250, DM England, 1974에서 잠재적인 주소 지정 작업의 다이어그램.
이러한 아키텍처는 1970년대-1980년대에 엄청나게 진보적이고 진보된 것으로 간주되었으며 많은 회사와 연구 그룹, CAP 컴퓨터 기계(Cambridge, 1970-1977), Flex Computer System(Royal Signals and Radar Establishment, 1970s), Three Rivers PERQ(Carnegie Mellon University 및 ICL, 1980-1985) 및 가장 유명하게 실패한 Intel iAPX 432 마이크로프로세서(1981).
90년대와 1960년대에 가장 독창적이고 이상한 건축 솔루션의 1970%를 창시한 사람들이 미국인이 아니라 영국인(1980년대 - 일본인, 유사한 결과를 가짐)이었다는 것은 웃기는 일입니다.
영국 과학자들(예, 바로 그 사람들입니다!)은 파도의 정점에 머물고 뛰어난 컴퓨터 과학 이론가로서의 자격을 확인하기 위해 최선을 다했습니다. 유일한 안타까운 점은 소련의 컴퓨터 학문적 발전의 경우와 마찬가지로 이 모든 프로젝트가 서류상으로만 경이적이었다는 것입니다.
ICL은 세계 일류 첨단철 제조회사로의 진출을 필사적으로 시도했지만, 아쉽게도 실패했습니다.
미국인들은 처음에 튜링 시대부터 IT에 대한 선구적인 공헌을 한 앵글로색슨 동료들이 나쁜 조언을 하지 않을 것이라고 생각했고 두 번 심하게 화상을 입었고 Intel iAPX 432와 IBM System/38은 비참하게 실패했습니다. 1980년대 중반에 현대 프로세서 아키텍처로 큰 전환을 일으켰습니다(그때 미국 컴퓨터 공학 학교에서 RISC 기계의 원리를 발견했습니다. 이러한 패턴에 따라 구축됨).

CAP 컴퓨터는 여전히 캠브리지 연구소, IBM System/38 프로토타입 및 Three Rivers PERQ 워크스테이션에 있습니다(사진 https://en.wikipedia.org 및 https://www.chiark.greenend.org.uk).
때로는 흥미롭습니다. 본격적인 소비에트-영국 학교가 1980년대까지 진보된 생산 문화, 우리의 공통된 미친 아이디어 및 수십억 달러를 개발에 투입할 수 있는 소련의 능력으로 어떤 개발을 전개했을까요?
이러한 기회가 영원히 닫혀 있다는 것은 불행한 일입니다.
당연히 ITMiVT가 맨체스터 대학교(1960년대 초반부터 BESM-6에 대한 작업)와 훌륭한 접촉을 갖고 있었고 ICL은 Lebedev가 그렇게 동맹을 맺기를 원했습니다. 그러나 Burroughs는 태그 설명자 기계의 유일한 상업적 구현이었습니다.
Burtsev의 이 기계 작업에 대해 무엇을 말할 수 있습니까?
러시아 Burroughs의 놀라운 모험
소비에트 컴퓨팅은 극도로 폐쇄된 영역이었습니다. 많은 기계에는 사진이 없고 합리적인 설명(예: Kitovskaya M-100의 아키텍처에 대해 지금까지 알려진 것이 없음)이 없으며 일반적으로 모든 단계에서 놀라움이 기다리고 있습니다(예: 2010년대 컴퓨터 "볼가(Volga)"의 발견, 수십 번의 인터뷰를 하고 이를 기반으로 책을 쓴 Revich, Malinovsky 및 Malashevich도 그 존재를 의심하지 않았습니다.
그러나 한 특정 지역에는 군용 차량보다 더 많은 침묵과 비밀이있었습니다. 이것은 연합에서 작동했던 미국 컴퓨터에 대한 참조입니다.
이 주제는 Dubna에 있는 잘 알려진 CDC 6500을 제외하고는 소련에 하나의 클래스로 미국 컴퓨터가 전혀 없다는 인상을 받을 정도로 제기되는 것이 너무 싫었습니다.
CYBER 170과 172에 대한 정보조차 조금씩 채굴해야 했지만(그리고 소련 과학 아카데미와 다른 많은 곳에 HP 3000이 있었습니다!), 연합에 실제 살아있는 Burroughs의 존재는 많은 것은 신화가 될 것입니다.
단일 러시아어 소스, 인터뷰, 포럼, 책에는 소련에서 이러한 기계의 운명에 전념하는 라인조차 포함되어 있지 않습니다. 그러나 언제나처럼 서양 친구들은 우리 자신보다 우리에 대해 훨씬 더 많이 알고 있습니다.
주의 깊은 검색 결과, Burroughs는 Social Block에서 매우 사랑받았으며 여기의 국내 공급원이 그들의 입에 물을 가져갔음에도 불구하고 강력하게 사용되었다는 것이 확립되었습니다.
다행히도 미국에는 메인프레임의 각 모델에 대한 전체 설치 수와 일련 번호에 이르기까지 모든 것을 알고 있는 이 아키텍처의 팬이 충분합니다. 그들은 이 정보를 표로 요약하여 아낌없이 공유했으며 문서에는 Burroughs 컴퓨터가 바르샤바 조약 국가로 배송될 때마다 정보 출처도 포함되어 있습니다.
그럼, 소련 조달의 비밀을 우리에게 알려주는 냉전 중 경제 전략: 미국 무역 금수 조치에 대한 유럽의 대응을 살펴보겠습니다.
1969년 5500월 초에 행정부 간 직원 연구 그룹... 이 무렵 미국 컴퓨터 회사는 동유럽에서 판매를 시작했습니다. 디트로이트의 Burroughs Corporation은 IBM 컴퓨터의 중급 수준에 해당하는 대형 BXNUMX 컴퓨터 XNUMX대를 체코슬로바키아에, 모스크바에 XNUMX대를 설치했습니다. 소련 프로그래머와 유지 보수 직원은 디트로이트 공장에서 교육을 받았습니다.
오, 1969년까지 Burroughs B5500이 모스크바에 설치되었을 뿐만 아니라 소련 전문가들도 디트로이트에 있는 회사 공장에서 인턴십을 하게 되었습니다!
정부 명령에 따라 또 다른 4대의 자동차가 체코슬로바키아에 판매되었습니다. 불행히도 어디에 설치되고 무엇을 했는지는 알 수 없지만 분명히 대학에서는 알 수 없습니다. 표의 "사용자" 열은 "정부"를 나타냅니다. 가장 강력한 B6700(나중에 B7700으로 업그레이드됨!)은 동독에서 판매되었으며 칼스루에 대학에서 사용되었습니다.
모스크바로의 배송에 대한 정보를 명확히 하기 위해 우리는 Southwest Museum of Engineering, Communications and Computation(미국 애리조나)에 연락해야 했습니다.
그들의 웹사이트에서 ACM의 Computer Architecture News(Alastair JW Mayer, Architecture of the Burroughs B1982 – 5000 Years Later and Still Ahead the Times)의 20년 기사에 대한 각주를 찾을 수 있습니다. 엔지니어 Rea Williams의 편지입니다. ) Burroughs Corporation 설치 및 지원 팀에서:
정확히는 1973년경으로 기억나지 않습니다. Burroughs는 B6500(B6700)을 러시아 석유부에 판매했습니다. 키릴 자모 인쇄기, 특수 종이 테이프 판독기 및 기타 매우 특별한 것들이 있는 매우 특별한 시스템이었습니다. 이것은 냉전 기간 동안이었지만 우리(Burroughs)는 시스템 공급에 대한 몇 가지 특별 허가를 받았습니다. 나는 산업 도시 공장에서 "라이드 아웃"시스템에 참여했습니다. Glen은 우리 TIO 조직과 함께 있었고 러시아로 가서 현지 사람들이 유지 관리하도록 교육하고 설치하는 일을 도왔습니다. 그는 Burrough 사람들이 "협력"하고 있다고 생각하고 방 문을 열어 두어야 만했기 때문에 GRU 또는 그들의 카드 게임을 불신하는 모든 것에 대한 이야기를 했습니다. 멋진 이야기, 모두 기억할 수 있기를 바랍니다. 그래서 결국 그는 나에게 핀을 주었다. 나는 나중에 당신에게 말할 것인 다른 것들도 주변에 있습니다.
그건 그렇고, 그러한 행사를 기리기 위해 소련은 Burroughs 엠블럼과 "Barrows"라는 글자가있는 기념 배지를 발행하여 프로젝트 참가자에게 배포했습니다. Williams의 원래 배지가 이 기사의 제목을 장식합니다.
따라서 소비에트 석유 산업(일반적으로 우리의 군대 및 과학 컴퓨터 주변에서 일어나고 있는 모든 불법과 평행)은 매우 영향력 있고 부유하며 아카데미와 당의 모든 대결에서 무한히 멀리 떨어져 있으며 만족하기를 원하지 않습니다. 가정용 컴퓨터(그리고 소련 연구소의 누군가에게 주문하고 6700년 간의 대결 끝에 모두 실패할 때까지 기다리는 것은 절대 원하지 않음)는 침착하게 그것을 받아 그녀가 할 수 있는 최선의 것인 우수한 BXNUMX을 샀습니다. 그들은 귀중한 기계가 제대로 작동하도록 하기 위해 회사 내부에서 설치 팀을 호출하기도 했습니다.
정말 진지한 사람들(석유 노동자들이 대부분의 돈을 국가에 가져갔고, 군대와 학자들이 게임에 썼음을 잊지 말자)이 국산차를 취급했다는 사실을 여실히 보여주는 이번 에피소드는 더 강한.

University of Tasmania의 Burroughs B6700 및 Burroughs Large Systems 라인의 최신 - 위대한 B7900(http://www.retrocomputingtasmania.com, https://pretty-little-fools.tumblr.com)
우리는 두 가지 흥미로운 사실에 주목합니다.
첫째, 모든 사람이 Burroughs가 주로 미국 연방 준비 제도 이사회에 대한 메인프레임(보안 아키텍처의 황금 표준) 공급에 대해 알고 있음에도 불구하고 군사 명령도 받았습니다(IBM 및 Sperry보다 훨씬 적기는 하지만 제XNUMX차 세계 대전 기간 동안 전쟁에서 그들은 정부와 연락을 취하지 못했습니다).
게다가 그들의 자동차는 대학을 매우 좋아했습니다. 영국, 프랑스, 독일, 일본, 캐나다, 호주, 핀란드, 심지어 뉴질랜드까지 전 세계적으로 사랑받았다고 말할 수도 있습니다. 다양한 라인의 Burroughs 메인프레임이 XNUMX개 이상 설치되었습니다. 건축학적으로(그리고 스타일 면에서) Burroughs는 대형 컴퓨터의 Apple이었습니다.
그들의 기계는 견고하고 놀라울 정도로 신뢰할 수 있고 비싸고 강력했으며 사전 설치 및 구성된 모든 소프트웨어 및 소프트웨어 패키지가 포함된 절대 키트로 제공되었으며 아키텍처는 시장에 나와 있는 것과는 다른 폐쇄형이었습니다.
Burroughs(황금 시대의 Macintosh와 마찬가지로)는 플러그 앤 플레이만 하기 때문에 모든 지식인에게 사랑받았습니다. 그 당시 메인프레임의 기준에 따르면 S/360만큼 성공적이었음에도 믿을 수 없을 정도로 훌륭했습니다.
그리고 물론 디자인, 편리한 터미널 브랜드, 오리지널 디스크 로딩 시스템 및 기타 여러 가지가 다릅니다. 우리는 또한 수년 동안 슈퍼 컴퓨터는 아니지만 약 2 MFLOPS를 생산하는 강력한 작업 기계였습니다. 그 당시 소련이 가지고 있던 것보다 몇 배나 강력합니다.
일반적으로 대학은 당연히 그들을 사랑했고, 따라서 Burroughs를 Union에서 과학 슈퍼컴퓨터로 사용하는 것은 완전히 정당한 결정이 될 것입니다. 별도의 보너스는 먼저 고등 교육(특히 유럽)의 황금 표준으로 간주되는 언어인 Algol에 대한 하드웨어 지원이었고, 두 번째로 다른 아키텍처에서는 매우 느렸습니다.
Algol(순수한 가정용 기계에서는 완전한 지원이 나타나지 않음)은 고전적 학술 구조적 프로그래밍의 표준으로 당연히 간주되었습니다. PL/I와 같은 난해한 구성으로 과부하가 걸리지 않고 Pure C만큼 무질서하지도 않고 Fortran보다 몇 배 더 편리하고 LISP 및 (God forbid) Prolog보다 훨씬 덜 복잡합니다.
OOP라는 개념이 등장하기 전에 더 완벽하고 더 편리한 것은 없었고 Burroughs는 속도가 느려지지 않은 유일한 기계였습니다.
또 다른 사실은 큰 주목을 받을 가치가 있습니다.
KoCom은 우리가 고급 아키텍처를 구매하는 것을 절대적으로 허용하지 않았습니다. 1980년대의 강력한 워크스테이션에 대한 제한도 소련이 붕괴된 후에야 해제되었습니다. 우리는 CDC를 위해 치열하게 싸워야 했습니다. Control Data의 이사는 이미 의회의 반미 활동에 의해 조사를 받고 있었고, 미국의 이익을 목표로 여러 기계가 설치되었습니다.
수문기상센터의 CYBER는 북극 기후 데이터 지원을 위해, CYBER LIAN은 재귀 컴퓨터 공동 개발을 약속하는 대가로 주어졌습니다.
결과적으로, 그건 그렇고, 그들은 헛되이 팔렸고 공동 작업은 효과가 없었습니다.
이 아이디어의 진정한 저자인 토르가쇼프(Torgashov)는 양키스와 함께 일하면서 얻은 명성과 돈이 눈앞에 다가오자 그의 상사들에 의해 재빨리 지옥에 떨어졌습니다. 미국인들은 도착했고, 일반 기계가 어떻게 작동하는지 상상하기 어려웠던 보스로부터 개발에 관한 몇 가지 제스처를 얻으려고 시도하고 결국 모든 것에 침을 뱉고 떠났습니다.
그래서 소련은 세계 시장에 진출할 또 다른 기회를 잃었습니다.
그러나 신선한 Burroughs는 눈 깜박임 없이 우리에게 배달되고 CoCom도 의회도 반대하지 않으며 불만도 없습니다. 이것은 다시 대기업의 이익에 의해서만 정당화될 수 있습니다.
그들은 분명히 군대에 대한 자신의 매력을 포기하지 않을 것이라는 보장과 함께 그것을 석유 상인에게 팔았습니다. 그들 자신이 필요했지만 소련 석유 산업과 친구가되는 것은 양측 모두에게 매우 유익합니다.
우리는 또한 우리가 이전 기사에서 쓴 것처럼 냉전의 강도가 크게 감소한 Brezhnev 시대에 Burroughs를 우리에게 판매하기 시작했음을 주목합니다. 동시에, 교활한 Yankees는 순전히 군사 기술(가장 강력한 CDC 6600 또는 Cray-1과 같은)로 상대를 밀어붙이는 데 서두르지 않았지만 소련 사업을 지원하는 데는 개의치 않았습니다.
그러나 1993년에 출판된 애리조나 대학의 Peter Wolcott의 경영학 박사 학위 논문: 고성능 컴퓨팅 사례(Case of High-Performance Computing)는 B6700이 1977년에 모스크바에 설치되었다고 명시하고 있습니다. 배송은 총 4년이 걸렸습니다!).
Elbrus에 대한 대부분의 예비 설계 작업은 Burtsev가 미국에서만 살아있는 자동차를 볼 수 있었던 1970년에서 1973년 사이에 완료되었습니다(불행하게도 그가 정확히 그곳에 갔을 때 정보는 없음).
이때 ITMiVT 엔지니어는 B6700에 대한 일반 문서(명령 아키텍처 및 기계의 블록 다이어그램)에만 액세스할 수 있었습니다. Wolcott은 1975-1976년(분명히 Burtsev의 여행 이후에 많은 서류를 가져옴)에 더 자세한 정보를 받았고 Elbrus의 구조가 일부 개선되고 변경되었다고 썼습니다.
마지막으로, 1977년에 개발자들은 모스크바 Burroughs를 자세히 연구하여 이미 생산 중인 문서를 변경하는 지속적인 프로세스를 포함하여 또 다른 업그레이드 물결을 일으켰습니다.
이 때문에 우리는 1960년대 중반에 그가 친숙해질 수 있었던 영국의 작품의 영향을 분명히 받고 Burtsev를 방문했음을 보장할 수 있습니다. 그리고 예, 그 당시에 태깅 디스크립터 기계의 방향은 실제로 "이론적 용어로 가장 강력한" 것으로 간주되었습니다. 즉, 영국의 거의 모든 학술 컴퓨터 과학에서 가장 유망한 것으로 지원되었습니다.
그런 면에서 엘브루스에 대한 작업은 당시 가장 앞선 연구와 일맥상통했고, 1980년대 중반에 세계가 완전히 다른 방향으로 돌아간 것은 영국 학자들의 잘못이 아니었다.
또한 이론적 기사에 따르면 Burtsev 팀은 자동차 제작에 성공하지 못했고 실제 Burroughs에 대한 문서에 익숙해지면 이 일이 어떻게 작동하는지 완전히 이해할 수 있었습니다.
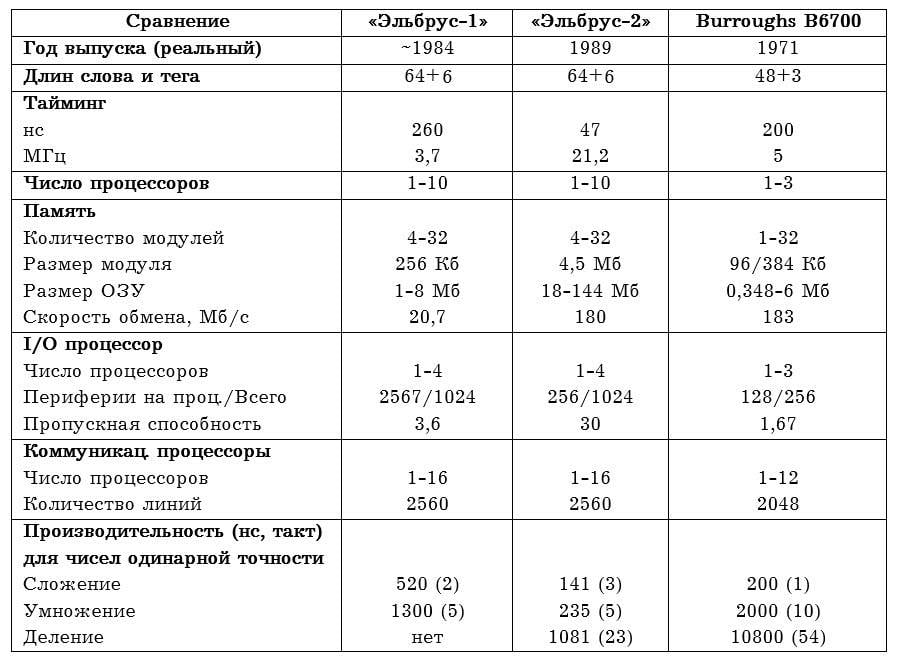
아키텍처 비교
Burroughs Large Systems Group의 전체 라인은 단일 B5000 아키텍처를 기반으로 구축되었습니다. 기계의 명칭은 매우 사치스러웠습니다. 마지막 세 자리는 기계의 세대를 나타내고 첫 번째는 세대의 전력 측면에서 일련 번호를 나타냅니다.
따라서 우리는 000 시리즈를 사용할 수 있었고(유일한 대표는 B5000의 조상임) 100에서 400까지의 숫자는 사용되지 않았고(중형 시스템 및 소형 시스템으로 이동) 다음 시리즈는 500 인덱스를 받았습니다. 그것은 세 대의 컴퓨터를 가지고 있었는데, 전력으로 나누어진 것 - 더 단순한 것(B5500), 더 복잡한 것(B6500), 그리고 이론상으로는 가장 강력한 것(B8500).
그러나 B6500은 이미 멈췄고 결과적으로 시리즈는 더 젊은 모델에 고정되었습니다. 그 다음 600번도 탈락(CDC와 혼동하지 않도록)하여 B5700, B6700, B7700 라인이 등장했다.
메모리 양, 프로세서 수 및 기타 구조적으로 중요하지 않은 세부 사항이 다릅니다. 마지막으로 800번째 시리즈는 6800개 모델(B7800, B900)과 5900번째 시리즈(B6900, B7900, BXNUMX)였다.
대형 시스템용으로 작성된 모든 코드는 기본적으로 재진입 가능하며 시스템 프로그래머는 이를 위해 추가 노력을 기울일 필요가 없습니다. 간단히 말해서, 프로그래머는 다중 사용자 모드에서 작동할 수 있다고 전혀 생각하지 않고 단순히 코드를 작성했고 시스템이 제어했습니다.
어셈블러가 없었고 시스템 언어는 ALGOL의 상위 집합이었습니다. ESPOL 언어(Executive Systems Problem Oriented Language)에서는 OS 커널(MCP, 마스터 제어 프로그램)과 모든 시스템 소프트웨어가 작성되었습니다.
700 시리즈에서는 보다 발전된 NEWP(New Executive Programming Language)로 대체되었습니다. 데이터에 대한 효율적인 작업을 위해 DCALGOL(데이터 통신 ALGOL) 및 DALGOL(데이터 관리 ALGOL) 확장이 추가로 개발되었으며, 효율적인 MCP 관리를 위해 별도의 명령줄 언어 WFL(Work Flow Language)이 등장했습니다.
Burroughs COBOL 및 Burroughs FORTRAN 컴파일러도 ALGOL로 작성되었으며 아키텍처의 모든 뉘앙스를 고려하도록 신중하게 최적화되었으므로 이러한 언어의 대형 시스템 버전은 시장에서 가장 빠릅니다.
대형 Burroughs 기계의 비트 깊이는 일반적으로 48비트(+3 태그 비트)였습니다. 프로그램은 8비트 음절로 구성되어 이름, 값 또는 연산자를 구성할 수 있으며 길이는 1음절에서 12음절까지 다양합니다(이것은 500 시리즈의 중요한 혁신이었습니다. 클래식 B5000은 길이가 12비트인 고정 명령어를 사용했습니다.
ESPOL 언어 자체에는 200개 미만의 명령문이 있었고 모두 8비트 음절에 맞습니다(강력한 줄 편집 연산자 등을 포함하여 명령이 없으면 120개 명령만 있음). MVST 및 HALT와 같이 운영 체제용으로 예약된 연산자를 제거하면 사용자 수준 프로그래머가 일반적으로 사용하는 집합은 100보다 작습니다. 일부 연산자(예: 이름 호출 및 값 호출)에는 명시적 주소 쌍이 포함될 수 있고 다른 연산자는 사용 고급 분기 스택.
Burroughs에는 프로그래머가 사용할 수 있는 레지스터가 없었습니다(머신의 경우 스택의 맨 위와 다음 레지스터는 레지스터 쌍으로 해석됨). 작업자가 작업할 필요가 없었으며 다양한 접미사/접두사 또한 모든 작업이 스택의 맨 위에 적용되었으므로 레지스터 간 작업을 수행하기 위한 옵션을 표시하는 데 필요하지 않았습니다. 이것은 코드를 극도로 조밀하고 간결하게 만들었습니다. 많은 연산자가 다형성이었고 태그로 정의된 데이터 유형에 따라 작업을 변경했습니다.
예를 들어, 대형 시스템 명령어 세트에는 하나의 ADD 문이 있습니다. 일반적인 최신 어셈블러에는 정수, 부동 소수점, 이중 및 long에 대한 add.i, add.f, add.d, add.l과 같이 각 데이터 유형에 대한 여러 덧셈 연산자가 포함되어 있습니다. Burroughs에서 아키텍처는 단정밀도 숫자와 배정밀도 숫자만 구분합니다. 정수는 지수 2이 있는 실수일 뿐입니다. 하나 또는 두 피연산자에 태그 0가 있으면 배정밀도 덧셈이 수행되고, 그렇지 않으면 태그 XNUMX이 단정밀도를 나타냅니다. 이것은 코드와 데이터가 결코 호환되지 않을 수 있음을 의미합니다.
Burroughs의 스택 작업은 매우 아름답게 구현되어 있습니다. 자세한 내용으로 독자를 지루하게 하지 않고 그냥 우리의 말을 받아들입니다.
산술 연산에는 한 음절이 필요하고 스택 연산(NAMC 및 VALC)에는 48개, 정적 분기(BRUN, BRFL 및 BRTR)에는 XNUMX개, 긴 리터럴(예: LTXNUMX)에는 XNUMX개가 필요합니다. 결과적으로 코드는 현대 RISC 아키텍처보다 훨씬 더 조밀했습니다(더 정확하게 말하면 더 많은 엔트로피를 가짐). 밀도를 높이면 명령 캐시 누락이 줄어들어 성능이 향상됩니다.
시스템 아키텍처에서 SMP - 최대 4개의 프로세서가 있는 대칭형 다중 프로세서(500 시리즈부터 800 시리즈에 있음, SMP는 NUMA - 비균일 메모리 액세스로 대체됨)에 주목합니다.
Burroughs는 일반적으로 고속 버스로 연결된 다중 프로세서 사용의 개척자였습니다. B7000 라인은 최대 8500개의 프로세서를 가질 수 있으며 그 중 적어도 하나는 I/O 모듈입니다. B16은 원래 XNUMX대였으나 결국 취소됐다.
Seymour Cray(및 Lebedev 및 Melnikov)와 달리 Burroughs 엔지니어는 대규모 병렬 아키텍처에 대한 아이디어를 개발했습니다. 즉, 하나의 초강력 벡터 하나를 사용하는 대신 상대적으로 약한 병렬 프로세서를 공통 메모리와 연결하는 것입니다.
보여진 바와 같이 역사 이 접근 방식이 결국 최고였습니다.
또한 Large Systems는 시장에 출시된 최초의 스택 머신이었으며 이들의 아이디어는 나중에 Forth 언어와 HP 3000 컴퓨터의 기반이 되었습니다. saguaro 스택(이것은 선인장과 같으므로 분기가 있는 스택이라고 함). 배열(문자열과 개체를 모두 포함할 수 있음)을 제외하고 모든 데이터는 스택에 저장되었으며 페이지는 가상 메모리에 할당되었습니다(이 기술의 첫 번째 상용 구현, S/360 이전).
Large Systems 아키텍처의 또 다른 잘 알려진 측면은 태그의 사용입니다. 이 개념은 원래 5000번째 시리즈부터 보안을 강화하기 위해 B500에 등장했습니다. 3비트가 아닌 1비트가 할당되어 총 8개의 태그 옵션을 사용할 수 있었습니다. 그 중 일부는 SCW(소프트웨어 제어 워드), RCW(리턴 제어 워드), PCW(프로그램 제어 워드) 등입니다. 아이디어의 장점은 비트 48이 읽기 전용이어서 사용자가 변경할 수 없는 제어 단어를 나타내는 홀수 태그가 있다는 것입니다.
스택은 매우 좋은데 구조 때문에 스택에 맞지 않는 개체(예: 문자열)로 작업하는 방법은 무엇입니까? 결국 어레이 작업을 위한 하드웨어 지원이 필요합니다.
아주 간단하게, Large Systems는 이를 위해 설명자를 사용합니다. 설명자는 이름에서 알 수 있듯이 I/O 요청 및 결과뿐만 아니라 구조의 저장 영역을 설명합니다. 각 설명자는 유형, 주소, 길이 및 데이터가 저장소에 저장되는지 여부를 나타내는 필드를 포함합니다. 당연히 자체 태그로 표시됩니다. Burroughs 디스크립터의 아키텍처도 매우 흥미롭지만 여기서는 자세히 설명하지 않고 가상 메모리가 이를 통해 구현되었다는 점에 유의합니다.
Burroughs와 대부분의 다른 아키텍처의 차이점은 페이지된 가상 메모리를 사용한다는 것입니다. 즉, 페이지는 정보 구조에 관계없이 고정된 크기의 청크로 페이지아웃됩니다. B5000 가상 메모리는 디스크립터로 설명되는 다양한 크기의 세그먼트와 함께 작동합니다.
ALGOL에서 배열 경계는 완전히 동적이며(이 의미에서 정적 배열이 있는 Pascal은 훨씬 더 원시적이지만 Burroughs Pascal 버전에서는 수정되었습니다!) Large Systems에서는 배열이 선언될 때 수동으로 할당되지 않습니다. , 그러나 액세스할 때 자동으로.
그 결과, C의 전설적인 malloc과 같은 저수준 메모리 할당 시스템 호출이 더 이상 필요하지 않습니다. 이것은 C가 그렇게 유명한 발의 모든 종류의 샷의 거대한 레이어를 제거하고 시스템 프로그래머를 절약합니다. 복잡하고 지루한 일상에서. 사실, Large Systems는 JAVA와 하드웨어에서 가비지 수집을 지원하는 시스템입니다!
아이러니하게도 1970년대와 1980년대에 Burroughs로 전환하고 C 언어에서 프로그램을 이식한 많은 Burroughs 사용자는 버퍼 오버런과 관련된 많은 오류를 발견했습니다.
1MB 이상의 메모리를 직접 지정할 수 없는 디스크립터 길이에 대한 물리적 제한 문제는 1970년대 후반 ASD(Advanced Segment Descriptors) 메커니즘의 출현으로 우아하게 해결되었습니다. 테라바이트의 RAM을 할당하십시오(개인용 컴퓨터에서는 2000년대 중반 - X에만 나타남).
또한, 소위. 가상 메모리 블록이 할당되었음을 의미하는 p-비트 인터럽트는 성능 분석을 위해 Burroughs에서 사용할 수 있습니다. 예를 들어, 이런 식으로 배열을 할당하는 프로시저가 지속적으로 호출되는 것을 알 수 있습니다. 가상 메모리에 액세스하면 성능이 크게 저하되므로 다른 RAM 칩을 연결하면 최신 컴퓨터가 더 빠르게 작동하기 시작합니다.
Burroughs 기계에서 p-비트 인터럽트를 분석함으로써 우리는 소프트웨어에서 시스템적 문제를 찾고 부하 균형을 더 잘 맞출 수 있었습니다. 이는 연중무휴 24x7 실행되는 메인프레임에 중요합니다. 대형 기계의 경우 하루에 몇 분이라도 시간을 절약하는 것이 최종 생산성 향상으로 이어졌습니다.
마지막으로 태그는 태그와 마찬가지로 코드 보안을 크게 향상시키는 역할을 했습니다. 해커가 최신 운영 체제를 손상시키기 위해 사용해야 하는 최고의 도구 중 하나는 고전적인 버퍼 오버플로입니다. 특히 C 언어는 데이터 스트림 자체에서 행 끝 신호기로 널 바이트를 사용하여 행 끝을 표시하는 가장 원시적이고 오류가 발생하기 쉬운 방법을 사용합니다(일반적으로 이러한 느슨함은 생성된 많은 것을 구별합니다. , 학문적 스타일, 즉 발달 분야의 특별한 자격은 없지만 똑똑한 사람들)이라고 말할 수 있습니다.
Burroughs에서 포인터는 inode로 구현됩니다. 인덱싱하는 동안 블록 경계 오버런을 피하기 위해 모든 증가/감소 시 하드웨어에서 검사합니다. 읽기 또는 복사하는 동안 데이터 무결성을 유지하기 위해 원본 및 대상 블록 모두 읽기 전용 설명자에 의해 제어됩니다.
그 결과 상당한 종류의 공격이 원칙적으로 불가능해지고, 소프트웨어의 많은 오류는 컴파일 단계에서도 포착될 수 있다.
Burroughs가 대학에서 그렇게 사랑받는 것은 놀라운 일이 아닙니다. 1960년대-1980년대에 자격을 갖춘 프로그래머는 일반적으로 대기업에서 일했고 과학자들은 스스로 소프트웨어를 작성했습니다. 결과적으로 Large Systems는 작업을 엄청나게 쉽게 만들어 어떤 프로그램에서도 근본적으로 망치는 것을 불가능하게 만들었습니다.
Burroughs는 수많은 기술에 영향을 미쳤습니다.
우리가 말했듯이 HP 3000 라인과 오늘날에도 여전히 사용되는 전설적인 계산기는 Large Systems 스택에서 영감을 받았습니다. Tandem Computers의 내결함성 서버도 이 엔지니어링 걸작의 흔적을 남겼습니다. Forth 외에도 Burroughs의 아이디어는 모든 OOP의 아버지인 Smalltalk와 JAVA 가상 머신의 아키텍처에 상당한 영향을 미쳤습니다.
왜 그런 위대한 기계가 사라졌습니까?
음, 첫째, 그들은 즉시 사라지지 않았습니다. 고전적인 실제 Burroughs 태그 설명자 아키텍처는 2010년까지 UNISYS 메인프레임 라인에서 계속 지속되었으며, 그제서야 평범한 Intel Xeon(IBM조차도 경쟁하기 매우 힘든 서버)의 서버에 자리를 잃었습니다. ). 변위는 1980년대의 다른 모든 이국적인 자동차를 죽인 한 가지 진부한 이유로 발생했습니다.
1990년대에는 DEC Alpha 및 Intel Pentium Pro와 같은 범용 프로세서가 엄청난 성능으로 펌핑되어 많은 정교한 아키텍처 트릭이 필요하지 않게 되었습니다. 1000MHz SuperSPARC-II 쌍의 SPARCserver-90E는 거북이와 같은 모든 옵션의 Elbrus를 이겼습니다.
Burroughs가 몰락한 두 번째 이유는 1980년대에 Apple을 거의 죽일 뻔했던 것과 동일한 문제였고, 메인프레임 비즈니스의 규모로 인해 악화되었습니다. 그들의 기계는 너무 복잡해서 개발하는 데 극도로 비용이 많이 들고 시간이 많이 걸리므로 기본적으로 1970년대 내내 동일한 아키텍처의 약간 개선된 버전만 만들었습니다. Burroughs가 다른 곳으로 이동하려고 하자마자(B6500 또는 B8500의 경우처럼) 프로젝트가 미끄러지기 시작했고 블랙홀의 속도로 돈을 흡수하고 결국 취소되었습니다(실패한 Apple III 및 Lisa처럼) .
메인프레임 규모로 인해 Burroughs는 엄청나게 비싼 유지 관리 비용으로 수백만 달러에 컴퓨터를 판매했습니다. 예를 들어 B8500은 16개의 프로세서를 탑재할 예정이었으나, 14개의 구성에도 예상 비용이 XNUMX만 달러 이상이어서 공급 계약이 해지됐다.
기계 자체의 엄청난 비용 외에도 회사의 구형 메인프레임은 지원을 위해 엄청난 금액을 요구했습니다. 최고급 B7800 모델의 경우 유지 보수, 서비스 및 모든 소프트웨어에 대한 모든 라이선스의 연간 패키지는 연간 약 1만 달러의 비용이 들지만 모든 사람이 이러한 사치를 누릴 수 있는 것은 아닙니다!
소비에트 오일맨이 풀 서비스를 구입했는지 아니면 강력한 말과 큰 망치로 Burroughs를 직접 수리했는지 궁금합니다.
따라서 Burroughs의 비즈니스는 IBM의 규모와 강점이 부족하여 항상 침체되어 있었습니다. 개발의 복잡성 때문에 값싼 차를 만들 수 없었고, 경쟁자들과의 치열한 전투로 고가의 차를 사는 사람들은 이익을 늘리고 개발에 추가 자금을 투자하고 가격을 낮추어 차의 경쟁력을 높일 수 있는 기회가 충분하지 않았습니다.
Sperry UNIVAC도 같은 문제를 겪었고 결국 1986년에 두 회사가 합병하여 살아남기 위해 UNISYS를 설립했으며 그 이후로 메인프레임을 생산해 왔습니다.
언급된 아키텍처 외에도 Burtsev는 하드웨어 오류 제어 측면에서 5E26 및 5E92b의 경험을 실제로 사용했습니다. 이 두 컴퓨터 모두 하드웨어 감지 및 XNUMX비트 오류 수정이 가능했으며 Elbrus 프로젝트에서 이 원칙을 새로운 차원으로 끌어 올렸습니다.
그래서 우리는 가장 매혹적인 질문에 대한 답변을 기다리고 있습니다. Elbrus El Burrows는 무엇입니까?
우리가 기억하는 것처럼 Ailif는 명령과 데이터의 선형 저장 장치인 기계인 고전적인 폰 노이만 모델을 포기했습니다. Burroughs의 saguaro 스택은 다중 사용자 다중 프로그래밍 환경에서 병렬 코드의 실행과 프로세스 계층을 반영하는 트리 구조였습니다. 그건 그렇고, 블록 계층 구조를 가진 ALGOL은 스택에 완벽하게 맞습니다. 이것이 Large Systems에서 구현이 성공한 이유입니다.
이러한 통합 설계 철학은 Elbrus 시스템 설계자들이 이를 새로운 차원으로 끌어올린 것입니다. 특히 ITMiVT의 개발자 그룹은 여러 개의 특수 언어 대신 Algol과 유사한 하나의 범용 El-76을 만들었습니다.
건축적 참신함은 여기서 끝나지 않았습니다.
기계의 직접적인 비교는 아래 표에 나와 있습니다. 구형 B6700은 전체적으로 17년 더 어린 컴퓨터의 배경과 잘 어울립니다.
흥미로운 점에서 - B6700과 달리 Elbrus는 엄청나게 거대했습니다.
첫 번째 버전은 300제곱미터를 차지했습니다. 단일 프로세서의 m 및 1제곱미터 m은 270개 프로세서 구성에서, 두 번째는 각각 10개 및 놀라운 420제곱미터입니다. m, 따라서 IBM AN / FSQ-2 Project SAGE 자체에서 역사상 가장 큰 컴퓨터의 월계관을 빼앗아 갔으며, 이는 튜브 하나인 260제곱미터를 차지했습니다. 중.

규모를 이해합니다. 웸블리 스타디움. A-135 미사일 방어 시스템을 위한 Elbrus 다중 기계 단지가 대략 그렇게 많이 차지했습니다.
두 시스템의 CPU는 역 폴란드 표기법을 사용하는 CISC 스택 아키텍처를 기반으로 합니다. 컴파일된 프로그램의 코드는 세그먼트 세트로 구성됩니다. 세그먼트는 일반적으로 프로그램의 한 프로시저 또는 블록에 해당합니다. 프로그램 실행이 시작되면 두 개의 메모리 위치가 할당됩니다. 하나는 스택용이고 다른 하나는 RAM의 여러 프로그램 세그먼트를 참조하는 데 사용되는 세그먼트 사전용입니다. 코드 세그먼트 및 배열을 위한 메모리 영역은 요청 시 OS에 의해 할당됩니다.
두 시스템의 설명자는 실행 스레드 간에 자동 메모리 공유를 구성하여 코드 재진입을 담당합니다. 코드와 데이터는 태그로 엄격하게 구분되며 디스크립터를 사용하면 보호를 보장하면서 다른 사용자에 대해 다른 데이터 세트에서 동일한 코드를 실행할 수 있습니다.
두 컴퓨터 모두 동일한 특수 목적 레지스터(예: 각 머신에 스택 기반, 스택 제한 및 스택 상단 레지스터가 있음) 및 스택 관리 명령을 사용합니다.
Burroughs와 Elbrus는 매우 유사한 철학을 가지고 있지만 프로세서 자체의 설계에서 크게 다릅니다.
B6700 프로세서는 48비트 가산기, 주소 처리 장치, 4개의 기능 컨트롤러(프로그램, 산술, 문자열, 스택 조정, 인터럽트, 전송 및 메모리) 및 레지스터 세트로 구성됩니다. 후자는 51개의 48비트 데이터 레지스터(20개의 최상위 스택 요소, 현재 값, 중간 값) 및 32개의 8비트 명령 레지스터(현재 실행 중인 프로시저에 대한 진입점 저장을 담당하는 XNUMX개의 디스플레이 레지스터 및 각각 XNUMX개의 기본 레지스터)를 포함합니다. 및 인덱스 레지스터).
프로세서에서 가장 흥미로운 것은 소위 극도로 까다로운 블록이었습니다. 사용 가능한 기능 블록에서 각 명령에 대한 계산 파이프라인을 구축한 작업 제품군의 컨트롤러(10개 분량). 이를 통해 트랜지스터 비용을 크게 줄일 수 있었습니다.
컨트롤러는 디코딩된 명령을 현재 프로그램 명령 워드 레지스터로 전달하고 적절한 연산자 제품군 컨트롤러를 선택합니다. 주요 기능은 명령어가 컴파일러에서 지시한 순서대로 엄격하게 순차적으로 실행된다는 것입니다. CPU에 가산기가 하나만 있기 때문에 산술 명령어는 겹칠 수 없습니다.
이것이 Elbrus 프로세서의 주요 차이점이었습니다. Babayan은 자랑스럽게 주먹으로 가슴을 치며 "세계 최초의 Elbrus 슈퍼스칼라"(그는 개발과 전혀 관련이 없음)를 선언했지만 실제로 Burtsev는 배우기 위해 위대한 CDC 6600의 아키텍처를 주의 깊게 연구했습니다. 병렬 컨베이어에서 기능 블록 그룹 간의 상호 작용의 비밀.
CDC 6600에서 Elbrus는 가산기, 승수, 분할기, 논리 블록, BCD 인코딩 변환 블록, 피연산자 호출 블록, 피연산자 쓰기 블록, 문자열 처리 블록, 서브루틴 실행 블록 및 인덱싱과 같은 여러 기능 블록(총 10개)의 아키텍처를 차용했습니다. 블록.
이러한 블록과 B6700 컨트롤러 사이에는 기능적으로 겹치는 부분이 있지만 Elbrus의 산술에는 하나가 아닌 4개의 독립적인 그룹이 있는 것과 같은 중요한 차이점도 있습니다.
여러 ALU는 이미 다른 시스템에서 사용되었지만 전 세계적으로는 스택 프로세서에서 사용된 적이 없습니다. 당연히 이것은 서구 개발자의 큰 어리 석음 때문에 수행되지 않았습니다. 스택은 정의에 따라 주소 지정이 XNUMX이라고 가정합니다. 필요한 모든 피연산자는 맨 위에 있어야 합니다. 분명히, 기존 주소가 없는 경우 사이클당 하나의 작업만 맨 위를 올바르게 지정할 수 있습니다. 이는 기본적으로 병렬 블록의 작업을 제외합니다.
Burtsev의 그룹은 이 제한을 피하기 위해 엄청나게 변태해야 했습니다.
사실, Elbrus 버전의 B6700 스택 프로세서는 더 이상 스택 프로세서가 아닙니다! 기적은 일어나지 않고 고슴도치는 뱀과 교배하지 않으므로 프로그래머에게 보이지 않는 내부 아키텍처는 고전적인 레지스터로 만들어야 했습니다. 컨트롤러는 평소와 같이 명령을 수신하고 디코딩한 다음 내부 레지스터 형식으로 변환합니다. B6700은 스택의 상위 2개 요소만 내부 레지스터로 해석했습니다. Elbrus - 32개 요소! 사실 스택에서 남은 이름은 하나뿐입니다.
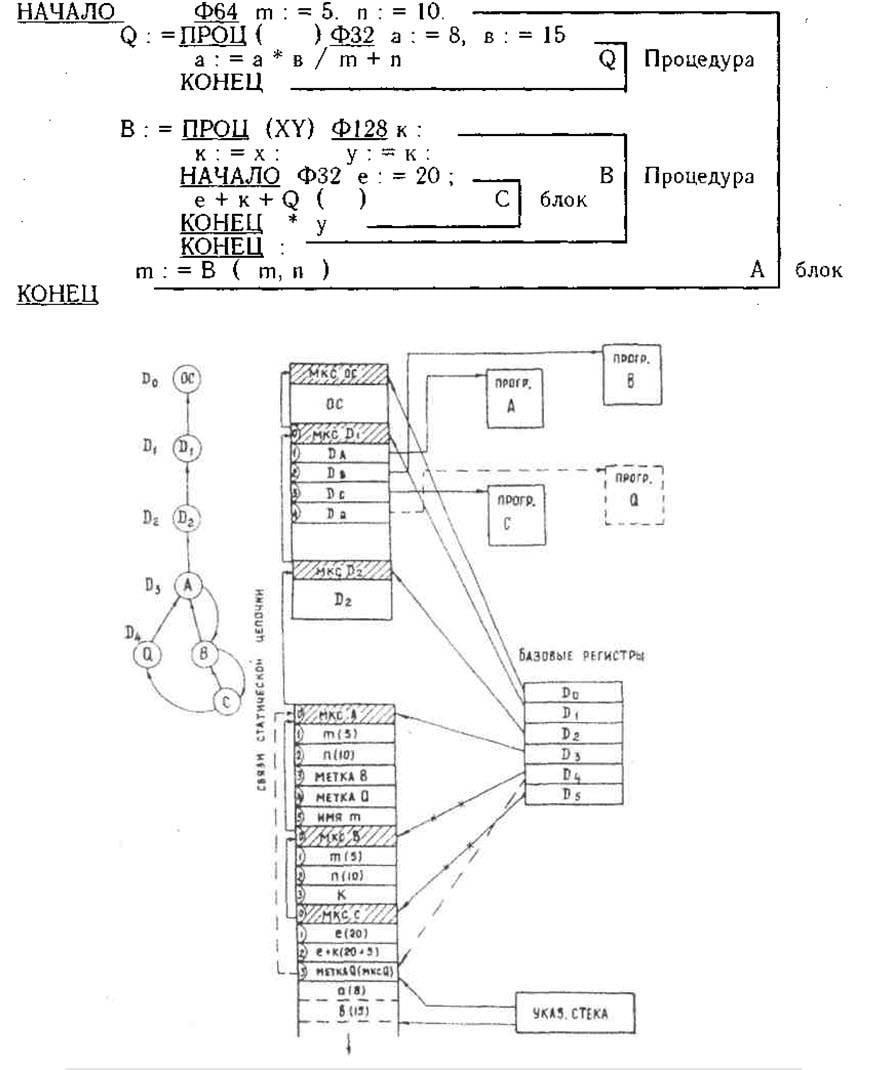
절차 Q로 전환하는 순간 Elbrus pseudostack의 상태. Burtsev의 기사 "Principles of building multiprocessor computing systems Elbrus"에서.
당연히 CU가 모든 기능 장치를 병렬로 로드할 수 없는 경우 완전히 쓸모가 없습니다. 이것이 투기적 실행의 메커니즘이 개발된 방식이며, 또한 절대적으로 독창적입니다.
Elbrus 명령어는 필요한 모든 피연산자를 사용할 수 있기 전에 기능 블록에 전달할 수 있으며 로드되면 단순히 데이터를 기다립니다. 실제로 실행은 데이터 흐름 아키텍처의 원칙에 따라 발생하며 정확한 실행 순서는 피연산자를 사용할 수 있게 되는 순서에 따라 다릅니다.
그들은 결국 무엇을 얻었습니까?
글쎄요, 그런 과감한 결정에 대한 현대 프로그래머의 반응은 분명합니다.
배열 작업이 나를 죽인 것을 기억합니다. 어레이를 할당하기 위해 수퍼바이저 모드로 전환하는 것이 정상입니까? 실행 파이프라인이 배열에 대해 아는 것이 정상입니까? 설명자를 통해 배열로 작업하는 것이 효율적입니까? 범위를 벗어난 입력이 확인하는 것이 더 빠르죠? 이 공포가 장비에 어떻게 떨어질지 상상하는 것은 무섭습니다. 그러나 그 당시에는 레이턴시와 메모리 및 기타 구성 요소의 속도와 함께 다른 레이아웃이 있었고 지금과 전혀 같지 않습니다. 그녀는 그러한 대담한 움직임을 정당화할 수 있었지만 그러한 디자인은 어떤 식으로든 살아 있지 않습니다. 사실 그들은 살아남지 못했다...
이론적으로 순수 태그 머신의 개발자는 1970년대 중반에 최소한 일부 자동 코드 병렬화를 수행할 수 있는 아키텍처와 컴파일러가 아직 없었기 때문에 대부분의 다중 프로세서 시스템을 효율적으로 로드할 수 없다는 사실에서 시작했습니다. 실행 유닛은 종종 유휴 상태였습니다. 이 교착 상태에서 벗어나는 방법은 수퍼스칼라 아키텍처 또는 악명 높은 VLIW 기계였지만 여전히 멀었습니다(6600년 CDC1965에서 동일한 Cray가 최초의 수퍼스칼라 프로세서를 사용했지만 여기에서는 아직 대량 생산의 냄새가 나지 않았습니다. ). 그래서 아키텍처를 Java 언어로 전환하여 프로그래머의 작업을 용이하게 하려는 아이디어가 탄생했습니다. 그러나 스택 아키텍처에서 좋은 슈퍼스칼라를 만드는 것은 쉽지 않습니다. RISC 명령 시스템을 만드는 것은 훨씬 쉽습니다. Elbrus-2에 어떤 종류의 슈퍼스칼라가 있는지 봅시다. 가장 일반적인 명령 조합은 최대 속도로 처리됩니다. 값과 산술 명령을 읽습니다. 주소를 로드하고 배열 요소를 가져옵니다. 주소를 다운로드하여 적어 두십시오."
В результате мы имеем, то, что имеем – суперскаляр на две инструкции за такт, причем примитивнейшие инструкции. Гордиться тут нечем, хорошо хоть чтение данных умеют на арифметику накладывать (и то при попадании в кэш).
이론적으로 순수 태그 머신의 개발자는 1970년대 중반에 최소한 일부 자동 코드 병렬화를 수행할 수 있는 아키텍처와 컴파일러가 아직 없었기 때문에 대부분의 다중 프로세서 시스템을 효율적으로 로드할 수 없다는 사실에서 시작했습니다. 실행 유닛은 종종 유휴 상태였습니다. 이 교착 상태에서 벗어나는 방법은 수퍼스칼라 아키텍처 또는 악명 높은 VLIW 기계였지만 여전히 멀었습니다(6600년 CDC1965에서 동일한 Cray가 최초의 수퍼스칼라 프로세서를 사용했지만 여기에서는 아직 대량 생산의 냄새가 나지 않았습니다. ). 그래서 아키텍처를 Java 언어로 전환하여 프로그래머의 작업을 용이하게 하려는 아이디어가 탄생했습니다. 그러나 스택 아키텍처에서 좋은 슈퍼스칼라를 만드는 것은 쉽지 않습니다. RISC 명령 시스템을 만드는 것은 훨씬 쉽습니다. Elbrus-2에 어떤 종류의 슈퍼스칼라가 있는지 봅시다. 가장 일반적인 명령 조합은 최대 속도로 처리됩니다. 값과 산술 명령을 읽습니다. 주소를 로드하고 배열 요소를 가져옵니다. 주소를 다운로드하여 적어 두십시오."
В результате мы имеем, то, что имеем – суперскаляр на две инструкции за такт, причем примитивнейшие инструкции. Гордиться тут нечем, хорошо хоть чтение данных умеют на арифметику накладывать (и то при попадании в кэш).
원칙적으로 이러한 의미에서 소련은 스스로를 패배 시켰습니다. 이미 언급했듯이 Burroughs 기계는 건축가의 어리 석음 때문이 아니라 그러한 장식 없이는하지 않았습니다. 그들은 순수한 스택 아키텍처를 원했고 제대로 해냈습니다.
Elbrus에서는 스택의 우아한 단순성에서 하나의 이름이 남았지만 기계는 훨씬 더 비싸고 복잡해졌습니다(Elbrus 프로세서를 디버깅하는 것이 도대체 무엇인지, 이것을 한 사람이 나중에 알려줄 것입니다). 성능 면에서 여전히 실제로 승리하지 못했습니다. 두 종류의 기계 모두의 단점이 혼합되어 있습니다.
일반적으로 아이디어를 소비에트화하지 않고 그대로 훔치는 것, 즉 확장하고 심화하는 것이 더 나은 경우입니다.
어레이에 대해 어떤 것이 있었습니까?
Burtsev도 여기에 5개의 코펙을 넣었습니다.
Burroughs B6700에서 모든 어레이 요소는 어레이 디스크립터를 통한 인덱싱을 통해 간접적으로 액세스됩니다. 추가 주기가 필요합니다. Elbrus에서 그들은 이 주기를 제거하기로 결정하고 어레이 요소를 로컬 캐시에 미리 가져오기 위한 하드웨어 블록을 추가했습니다. 인덱스 블록은 메모리의 단계와 함께 현재 요소의 주소를 저장하는 연관 메모리를 포함합니다.
결과적으로 핸들은 배열의 첫 번째 요소를 꺼내는 데만 필요합니다. 다른 모든 사람들은 직접 연락할 수 있습니다. 연관 메모리는 5개의 배열에 대한 정보를 저장할 수 있으며 루프의 요소 주소를 계산하는 데 단 XNUMX주기가 걸리므로 루프의 XNUMX회 반복에 대한 배열 요소를 미리 추출할 수 있습니다.
이 혁신을 통해 개발자는 순전히 스칼라 머신으로 제작된 B6700에 비해 Elbrus에서 벡터 연산의 상당한 가속을 달성했습니다.
메모리 아키텍처도 상당한 변화를 겪었습니다.
B6700에는 캐시가 없었고 특수 목적 레지스터의 로컬 세트만 있었습니다. Elbrus에서 캐시는 512개의 개별 섹션으로 구성됩니다. 프로그램에 의해 실행된 명령어를 저장하기 위한 명령어 버퍼(256워드), 스택의 가장 활성(최상위) 부분을 저장하기 위한 스택 버퍼(256워드), 그렇지 않으면 저장됩니다. 메인 메모리에서; 사이클로 처리되는 어레이 요소를 저장하기 위한 어레이 버퍼(1워드); 다른 버퍼에 저장된 데이터 이외의 데이터에 대한 전역 데이터(024워드)용 연관 메모리. 여기에는 스택 버퍼에 맞지 않는 프로그램 전역 변수, 핸들 및 프로시저 로컬 데이터가 포함됩니다.
이 캐시 구성을 통해 공유 메모리 구성에 비교적 많은 수의 프로세서를 효과적으로 포함할 수 있습니다.
캐시를 다중 프로세서 시스템에 연결하는 데 어떤 문제가 있습니까?
사실 각 프로세서는 데이터의 자체 로컬 복사본을 가질 수 있지만 프로세서가 하나의 작업을 병렬로 처리하도록 하려면 캐시의 내용이 동일한지 확인해야 합니다.
이러한 검사를 캐시 일관성 유지라고 하며 수많은 RAM 액세스가 필요하므로 시스템 속도가 엄청나게 느려지고 전체 아이디어가 사라집니다. 이것이 바로 SMP 아키텍처의 프로세서 수(대칭형 다중 프로세서)가 4개를 거의 초과하지 않는 이유입니다(지금도 4개는 서버 마더보드의 고전적인 최대 소켓 수입니다).
IBM 3033(1978) 듀얼 프로세서 메인프레임은 캐시에서 변경된 데이터가 RAM에서 즉시 업데이트되는 단순한 저장 스루 설계를 사용했습니다.
IBM 3084(1982, 4 프로세서)는 캐시 항목을 덮어쓸 때까지 또는 다른 프로세서가 주 메모리의 해당 데이터 항목에 액세스할 때까지 RAM으로의 데이터 전송이 지연될 수 있는 고급 일관성 체계를 사용했습니다.
이것이 3 프로세서 B6700이 캐시 없이 수행한 이유입니다. 프로세서는 이미 너무 화려했습니다.
Elbrus의 캐시 일관성은 OS 아키텍트에게 잘 알려진 프로그램의 임계 섹션 개념을 사용하여 유지되었습니다. 여러 프로세서가 공유하는 리소스(데이터, 파일, 주변 장치)에 액세스하는 프로그램 부분은 액세스 시 특수 세마포어를 설정합니다. 즉, 임계 영역에 들어가는 것을 의미합니다. 그 후 리소스는 다른 모든 프로세서에 대해 차단됩니다. 그것을 떠난 후 자원은 다시 잠금 해제되었습니다.
임계 섹션이 평균 프로그램의 약 1%(최소한 개발자에 따르면)를 차지한다는 점을 감안할 때 캐시 공유 시간의 99%는 일관성을 유지하는 오버헤드를 발생시키지 않았습니다. 명령어 버퍼의 명령어는 정의에 따라 정적이므로 여러 캐시의 복사본이 동일하게 유지됩니다. 이것이 Elbrus가 최대 10개의 프로세서를 지원한 이유 중 하나입니다.
일반적으로 아키텍처는 세그먼트 캐시를 매우 초기에 사용한 예이며 비슷한 원리(스택 버퍼, 명령 버퍼 및 연관 메모리 버퍼)가 이미 B7700에 구현되었지만 대부분의 경우 1976년에 나왔습니다. Elbrus 아키텍처를 만드는 작업이 완료되었습니다.
따라서 Elbrus는 10개의 프로세서가 메모리를 공유하는 세계 최초의 범용 시스템 중 하나라는 칭호를 받을 자격이 있습니다.
기술적으로(Elbrus-2가 1989년에만 정상적으로 작동했다는 사실을 고려하여) 이 유형의 첫 번째 슈퍼컴퓨터는 8000개의 National Semiconductor NS12 프로세서를 탑재한 Sequent Balance 32032이었습니다(1984년, 1986개의 프로세서가 탑재된 Balance 21000 버전은 30년에 출시되었습니다. ) 그러나 아이디어 자체는 분명히 XNUMX년 전에 Burtsev 그룹에 왔습니다.
Elbrus 메모리 모델은 매우 효과적이었습니다.
예를 들어 S/360의 경우 620개의 메모리 액세스(ALGOL로 작성된 경우)에서 46(어셈블러로 작성된 경우), 396 및 54로 S/6의 경우 재할당이 필요한 여러 숫자를 추가하는 스타일의 간단한 프로그램 실행 BESM-23의 경우 "Elbrus"의 경우 XNUMX개뿐입니다.
Burroughs 기계와 마찬가지로 Elbrus는 태그를 사용하지만 그 사용은 여러 번 확장되었습니다.
Burtsev의 그룹은 가능한 한 많은 제어를 하드웨어에 전달하려는 열의에서 태그 길이를 6비트로 두 배로 늘렸습니다. 그 결과 기계는 반/단정밀도/배정밀도 피연산자, 정수/실수, 빈/전체 단어, 레이블("외부 인터럽트 블록이 없는 특권 레이블" 및 "주소 정보 없는 레이블 포함)"을 구별할 수 있었습니다. 레코더"), 세마포어, 제어 단어 및 기타.
레이블을 만드는 주요 목표 중 하나는 프로그래밍을 단순화하는 것이었습니다. 함수 블록이 실수와 정수 피연산자를 구별할 수 있다면 둘 중 하나에 대한 계산에 적응하도록 설계될 수 있으며 별도의 스칼라 및 실수 블록이 필요하지 않습니다.
실제로 Elbrus는 최신 OOP에 필적하는 수준에서 하드웨어에서 동적 타이핑을 구현했습니다.
태그의 또 다른 목적은 명령어에 대한 산술 연산을 수행하려는 시도와 같은 오류를 감지하는 것이었으며 태그는 메모리를 보호하고 특정 데이터의 쓰기를 제한하는 데에도 사용할 수 있습니다.
태그 분야에서 Elbrus는 기본 기계와 B6700의 아이디어를 새로운 차원의 정교함으로 가져왔습니다.
이 모든 것이 Burroughs 건축가가 달성하지 못한 것을 달성하는 것을 가능하게 했습니다. 우리가 기억하듯이 OS 코드 작성 및 후속 시스템 관리를 위해 별도의 ALGOL 확장이 필요했습니다. "Elbrus"의 개발자는 이 아이디어를 버리고 모든 것을 쓸 수 있는 하나의 완전한 범용 언어 "El-76"을 만들었습니다.
높은 수준의 언어로 전체 OS를 작성하려면(메모리 할당 및 프로세스 전환과 같은 가장 낮은 수준의 내부 작업을 담당하는 코드 포함) 매우 높은 수준의 특수 하드웨어가 필요합니다. 예를 들어, Elbrus OS의 프로세스 전환은 특수 하드웨어 레지스터에 대해 잘 정의된 작업을 수행하는 일련의 할당 연산자로 구현되었습니다.
Elbrus(특히 두 번째 버전)에 훨씬 더 많은 메모리가 포함되어 있지만 두 시스템의 RAM 디자인은 매우 유사합니다.
RAM "Elbrus"는 계층적으로 구성되며 메모리 섹션(1 캐비닛)은 4개의 모듈로 구성되며 각 모듈은 32단어의 16개 블록으로 구성됩니다. 섹션 간, 섹션 내 모듈 간, 개별 모듈 내 등 여러 수준에서 대체가 가능합니다. 한 사이클에서 각 메모리 모듈에서 최대 450개의 워드를 읽을 수 있습니다. 최대 메모리 대역폭은 180MB/s이지만 각 프로세서의 최대 데이터 전송 속도는 XNUMXMB/s입니다.
B6700과 Elbrus의 메모리 관리 방식은 일반적으로 매우 유사합니다. 메모리는 컴파일러에서 정의한 프로그램의 논리적 섹션을 나타내는 가변 길이 세그먼트로 구성됩니다. 프로그램의 논리적 구분에 따라 세그먼트는 서로 다른 보호 수준을 가질 수 있으며 프로세스 간에 공유될 수 있습니다.
B6700에서는 세그먼트가 전체적으로 메인 스토리지와 가상 스토리지 사이를 이동했습니다. 어레이는 예외였습니다. 그것들은 각각 256개 단어의 그룹으로 메인 메모리에 저장될 수 있으며, 단어를 연결함으로써 양쪽에 경계가 지정됩니다.
Elbrus에서 코드 세그먼트는 데이터 세그먼트 및 배열과 다르게 처리됩니다. 코드는 B6700과 같은 방식으로 처리되며 데이터와 배열은 각각 512단어의 페이지로 구성됩니다.
Elbrus 접근 방식은 여기에서 더 효율적이고 더 빠른 스와핑을 허용합니다.
또한 Elbrus는 보다 현대적인 유형의 가상 메모리를 사용합니다.
Burroughs 컴퓨터에서 주소 지정은 B20/220의 최대 물리적 메모리인 6700비트 또는 7700워드로 제한되었습니다. 주 메모리에 있는 세그먼트의 존재는 설명자의 특수 비트로 표시되며 프로세스 실행 중에 RAM에 남아 있습니다. 실제 메모리의 총량보다 큰 실제 가상 메모리 공간의 개념은 없었습니다. 디스크립터에는 물리적 주소만 포함됩니다.
Elbrus 기계는 프로그램 세그먼트에 대해 유사한 20비트 주소 지정 체계를 사용했지만 데이터 세그먼트 및 상수 배열에는 32비트 주소 지정이 사용되었습니다. 이것은 232바이트(4기가바이트)의 가상 메모리 공간을 제공했습니다. 이러한 세그먼트는 페이징 메모리 연관 블록에 저장된 페이징 테이블을 사용하여 가상 주소와 물리적 주소 사이를 변환하는 페이징 메커니즘을 사용하여 가상 메모리와 실제 메모리 간에 이동되었습니다. 가상 주소는 페이지 번호와 페이지 내의 오프셋으로 구성됩니다. 이것은 실제로 IBM 머신에서와 같이 가상 메모리의 완전한 현대적 구현입니다.
그래서 우리의 평결은 무엇입니까?
Elbrus는 Burroughs B6700(심지어 B7700)의 완전한 복제품이 아니었습니다.
더욱이 그는 그의 이념적 복제품이 아니라 그의 형제였습니다. 왜냐하면 B6700과 Elbrus는 동일한 소스에서 영감을 받았기 때문입니다. 베이스 머신에 대한 Ailif의 작업과 맨체스터 대학의 작업, 그리고 B5000의 공통 조상 -시리즈 자체인 유명한 B1은 Rice의 자동차 R6600에 구현된 아이디어의 개발이었습니다. 또한 Elbrus는 CDC 360을 영감(없는 경우)으로 사용했으며 가상 메모리 작업 측면에서 IBM S/81 모델 XNUMX을 사용했습니다.
이와 관련하여 우리는 의심의 여지없이 Elbrus의 건축 자체가 1970 년대의 세계 발전 추세에 절대적으로 있었고 그 대표자임을 인정합니다.
또한 여러 측면에서 B6700/7700보다 훨씬 더 발전했습니다.
아마도 수퍼 스칼라리즘을 달성하려는 시도만이 아키텍처(이미 언급한 대로 2-3 작업에 대한 수퍼 스칼라는 양초의 가치가 없음)와 실용적(결과적으로 이미 엄청나게 복잡한 프로세서는 훨씬 더 복잡해져서 거대한 T자형 캐비닛을 차지하고 디버깅이 거의 불가능해졌습니다.
불행히도 그러한 순간을 건너 뛰기 위해서는 세계 최고의 건축 사례와 함께 수년간 개발 된 엄청난 경험과 직감이 있어야합니다. 물론 이것은 Union에 없었습니다.
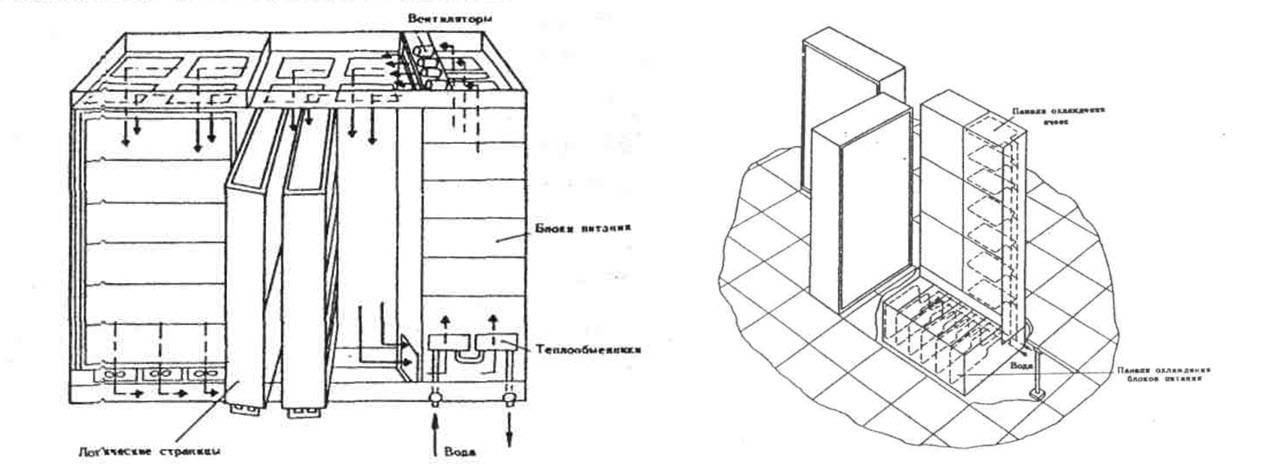
Burtsev의 기사 "컴퓨팅 프로세스의 병렬화 및 슈퍼컴퓨터 아키텍처 개발"의 일반적인 캐비닛 "Elbrus-1" 및 CPU "Elbrus-2". MVC "엘브루스".
당연히 Elbrus의 독창성에 대해 이야기해서는 안됩니다. 사실, 그것은 여러 가지 측면에서 크게 개선된 다양한 기술 솔루션의 모음일 뿐입니다.
그러나 이러한 관점에서 B5000은 우리가 이미 말했듯이 R1의 고도로 발전된 버전이기도 합니다.
이러한 아키텍처의 관련성에 대해서는 의심의 여지가 없습니다. 1970년대는 이미 오래전에 지나갔고 IT의 역사는 완전히 다른 방향으로 바뀌었고 40년 동안 그 자리를 지켜왔습니다.
따라서 서류상으로 1970년 기준의 "Elbrus"는 과소평가 없이 최고의 서구 자동차와 견줄만한 걸작이었습니다. 그리고 여기에 구현이 있습니다 ...
그러나 이것은 다음 기사의 주제입니다.
계속 될 ...
정보